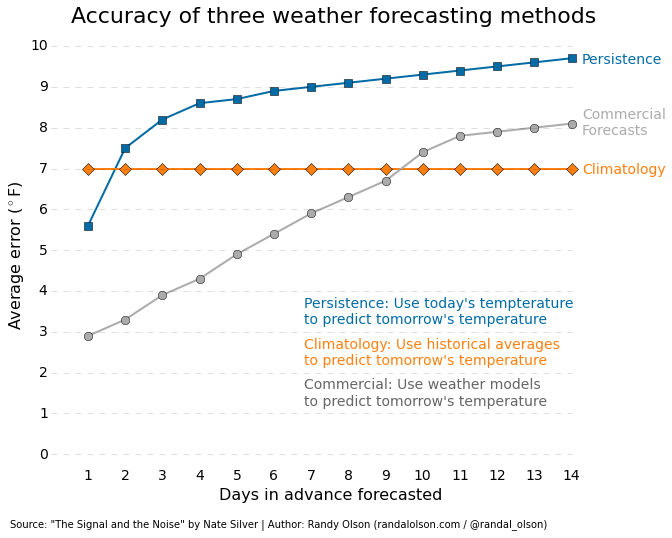
Accuracy of three major weather forecasting services
For the past month, I've been slowly working my way through Nate Silver's book, The Signal and the Noise. It's really a great read, but if you're a regular reader on this blog, I'd imagine you've already read it. This book is loaded with all kinds of great examples of where predictive analytics succeeds and fails, and I decided to highlight his weather forecasting example because of how surprising it was to me.
For those who aren't in the know: Most of the weather forecasts out there for the U.S. are originally based on data from the U.S. National Weather Service, a government-run agency tasked with measuring and predicting everything related to weather across all of North America. Commercial companies like The Weather Channel then build off of those data and forecasts and try to produce a "better" forecast -- a fairly lucky position to be in, if you consider that the NWS does a good portion of the heavy lifting for them.
We all rely on these weather forecasts to plan our day-to-day activities. For example, before planning a summer grill out over the weekend, we'll check our favorite weather web site to see whether it's going to rain. Of course, we're always left to wonder: Just how accurate are these forecasts? Plotted below is the accuracy of three major weather forecasting services. Note that a perfect forecast means that, e.g., the service forecasted a 20% chance of rain for 40 days of the year, and exactly 8 (20%) of those days actually had rain.
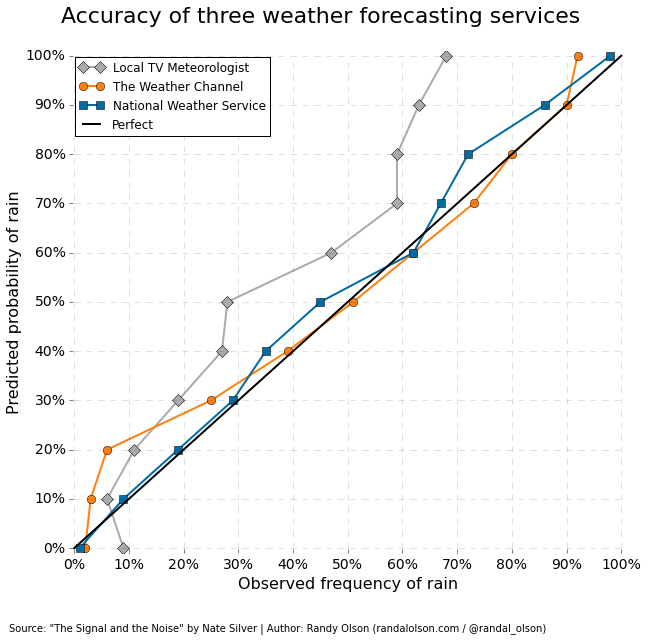
There's some pretty startling trends here. For one, The Weather Service is pretty accurate for the most part, and that's because they consistently try to provide the most accurate forecasts possible. They pride themselves on the fact that if you go to Weather.gov and it says there's a 60% chance of rain, there really is a 60% chance of rain that day.
With the advantage of having The Weather Service's forecasts and data as a starting point, it's perhaps unsurprising that The Weather Channel manages to be slightly more accurate in their forecasts. The only major inaccuracy they have, which is surprisingly consistent, is in the lower and higher probabilities of raining: Weather.com often forecasts that there's a higher probability of raining than there really is.
This phenomenon is commonly known as a wet bias, where weather forecasters will err toward predicting more rain than there really is. After all, we all take notice when forecasters say there won't be rain and it ends up raining (= ruined grill out!); but when they predict rain and it ends up not raining, we'll shrug it off and count ourselves lucky.
The worst part of this graph is the performance of local TV meteorologists. These guys consistently over-predict rain so much that it's difficult to place much confidence in their forecasts at all. As Silver notes:
TV weathermen they aren't bothering to make accurate forecasts because they figure the public won't believe them anyway. But the public shouldn't believe them, because the forecasts aren't accurate.
Even worse, some meteorologists have admitted that they purposely fudge their rain forecasts to improve ratings. What's a better way to keep you tuning in every day than to make you think it's raining all the time, and they're the only ones saving you from soaking your favorite outfit?
For me, the big lesson learned from this chapter in Silver's book is that I'll be tuning in to Weather.gov for my weather forecasts from now on. Most notably because, as Silver puts it:
The further you get from the government's original data, and the more consumer facing the forecasts, the worse this bias becomes. Forecasts "add value" by subtracting accuracy.

Dr. Randal S. Olson
AI Researcher & Builder · Co-Founder & CTO at Goodeye Labs
I turn ambitious AI ideas into business wins, bridging the gap between technical promise and real-world impact.