Here's Waldo: Computing the optimal search strategy for finding Waldo
As I found myself unexpectedly snowed in this weekend, I decided to take on a weekend project for fun. While searching for something to catch my fancy, I ran across an old Slate article claiming that they found a foolproof strategy for finding Waldo in the classic "Where's Waldo?" book series. Now, I'm no Waldo-spotting expert, but even I could tell that the strategy they proposed there is far from perfect.
That's when I decided what my weekend project would be: I was going to pull out every machine learning trick in my tool box to compute the optimal search strategy for finding Waldo. I was going to crush Slate's supposed foolproof strategy and carve a trail of defeated Waldo-searchers in my wake.
"But Randy, don't you have better things to work on? You know, curing cancer, solving world hunger... ANYTHING else?", a sane person would have said at that point.
Too bad that sane person wasn't around.
What is "Where's Waldo"?
For the poor souls who have no clue who Waldo is, I'll defer to the Wikipedia description:
"Where's Waldo?" is a series of children's books created by English illustrator Martin Handford. The books consist of a series of detailed double-page spread illustrations depicting dozens or more people doing a variety of amusing things at a given location.
Readers are challenged to find a character named [Waldo] hidden in the group. [Waldo's] distinctive red-and-white-striped shirt, bobble hat, and glasses make him slightly easier to recognize, but many illustrations contain "red herrings" involving deceptive use of red-and-white striped objects.
Here's an example of a classic "Where's Waldo?" illustration:

Here's Waldo
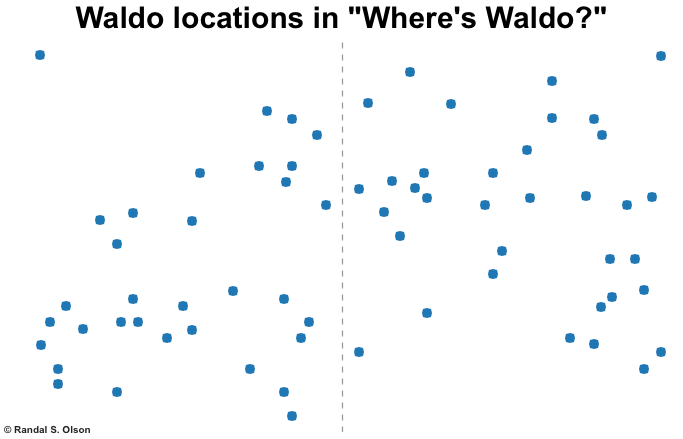
Thankfully, the Slate article provided a chart that made it dead easy to acquire all 68 of Waldo's coordinates in the primary 7 editions of the "Where's Waldo?" books. I've reproduced those coordinates visually below. You can download the data file here.
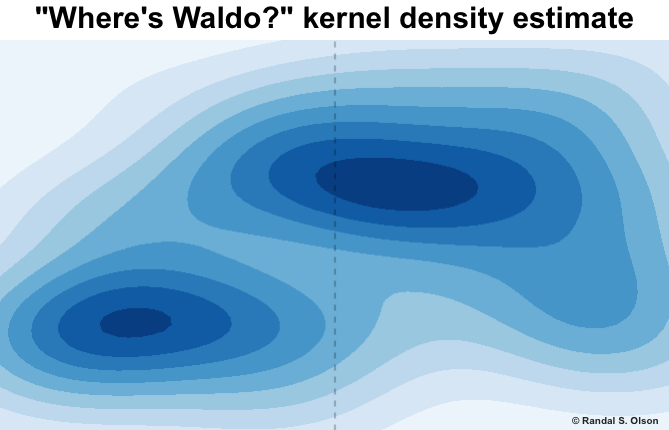
If we perform a kernel density estimation of these points, we start to see some interesting trends already:
- Waldo almost never appears in the top left corner. That's because there was always some postcard from Waldo in the top left corner describing the setting and some interesting facts about it.
- Waldo is rarely located on the edges. Slate's Ben Blatt hypothesized that this was done on purpose because the edges are "locations that might be construed as too obvious" and are "where children and adults alike might begin their search."
- Waldo is never located on the very bottom of the right page. I was unsure about the reason for this at first, but Chris Metzger offered a probable explanation: Whenever you flip to the next page in a book, the bottom of the right page is the first thing you see. Thus, the bottom of the right page would be one of the worst places to hide Waldo because that's the most-viewed part of the book.
Computing the optimal search strategy
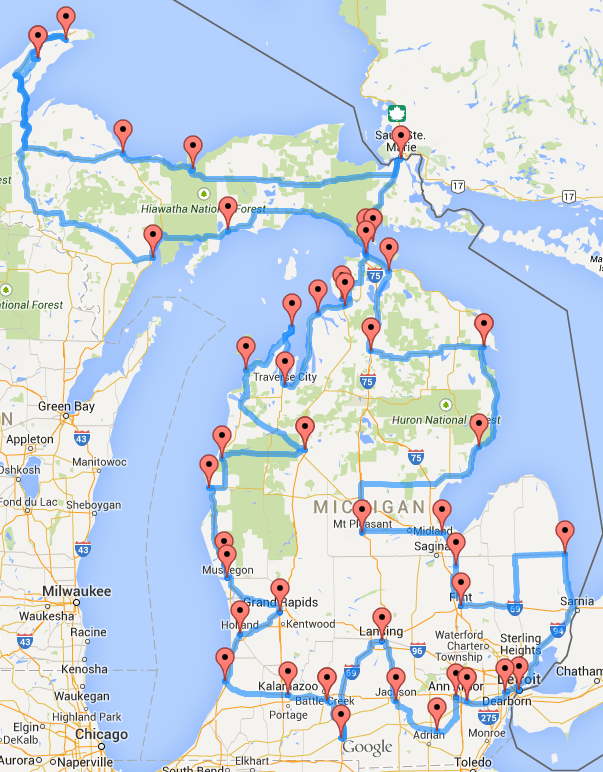
Now on to the real fun! I decided to approach this problem as a traveling salesman problem: We need to check every possible location that Waldo could be at while taking as little time as possible. That means we need to cover as much ground as possible without any backtracking.
In computer terms, that means we're making a list of all 68 points that Waldo could be at, then sorting them based on the order that we're going to visit them. So now we just need to try every possible arrangement of the points and find the one with the shortest distance traveled. Easy, right? Wrong.
Those 68 points can be arranged in ~2.48 x 1096 possible ways. To provide some context, that's more possible arrangements than the number of atoms in the universe. That's so many possible arrangements that even if finding Waldo became an international priority and the world banded together to dedicate the 8.25 million computing cores from the world's 10 largest supercomputers to the job, it would still take ~9.53 x 1077 years -- about 6.35 x 1067x longer than the universe has existed -- to exhaustively evaluate all possible combinations. (Generously assuming that each core could perform 10,000 evaluations per second.) In other words: if we don't have a smarter solution, Waldo is as gone as Carmen Sandiego.
Thankfully, there are plenty of smarter methods for approximating the optimal search path for finding Waldo. Below, I visualized the best solution over time of one such method -- a genetic algorithm -- that found a nearly-perfect solution. As you can see, genetic algorithms continually tinker with the solution -- always trying something slightly different from the current best solution and keeping the better one -- until they can't find a better solution any more.
(Note: Because genetic algorithms -- like many optimization algorithms -- are stochastic in nature, they won't always result in the exact same solution at the end.)
After running the genetic algorithm for about 5 minutes, I ended up with the solution below. I colored the paths by whether they're in the first (blue), second (orange), third (green), or final (red) 1/4 of the path. This path represents one of the shortest possible paths to follow on the page to find Waldo, so if we followed this path exactly, we'd most likely find Waldo much faster than someone following a more basic technique.
If you'd like to learn more about the methodology used here, see the accompanying methods and code document.
(For those interested: I also tried a standard hillclimber algorithm, but it always converged on a worse solution than the genetic algorithm.)
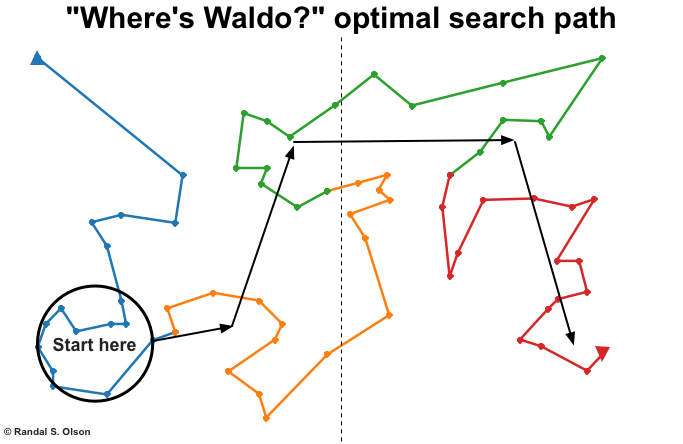
Of course, we should never take results from machine learning too literally. A robot might be able to follow this path perfectly, but I wouldn't be able to remember that path unless it was etched on every page for me. Instead, I think we can take some general lessons from the path that the genetic algorithm discovered:
- The bottom of the left page is a good place to start. If Waldo isn't on the bottom half of the left page, then he's probably not on the left page at all.
- The upper quarter of the right page is the next best place to look. Waldo seems to prefer to hide on the upper quarter of the right page.
- Next check the bottom right half of the right page. Waldo also has an aversion to the bottom left half of the right page. Don't bother looking there until you've exhausted the other hot spots.
I annotated the best solution with a general path to follow when searching for Waldo. If you don't find Waldo at the end of that trail, then you've got an outlier and should check the middle of the pages or the top left and right.
How does this strategy compare?
Unfortunately, I lost my old copies of "Where's Waldo?" ages ago in a move, so I couldn't test it out for myself. I'd love to put this strategy to the test, though, to see how much faster it is than the Slate strategy.
The U.S. publishers of "Where's Waldo?" generously sent me the entire series of books, so I was finally able to put this strategy to the test. As others have reported, the strategy works very well for most of the illustrations: I zoomed through most every illustration the first book spending <10 seconds on each illustration.
The trouble is when an outlier illustration comes along. When you're on an outlier illustration, you not only waste time following the path, but then you're left disoriented trying to trace back and worrying that you missed Waldo. Waldo-spotting performance degrades on these outlier illustrations, so don't be discouraged by Book 1, which has 4 (!) outliers in it.
Overall, in terms of speed, this machine-learning based method is streets ahead of the old Slate strategy.
Conclusions
This was all done in good humor and -- barring a situation where someone puts a gun to your head and forces you to find Waldo faster than their colleague -- I don't recommend actually using this strategy for casual "Where's Waldo?" reading. As with so many things in life, the joy of finding Waldo is in the journey, not the destination.

Dr. Randal S. Olson
AI Researcher & Builder · Co-Founder & CTO at Goodeye Labs
I turn ambitious AI ideas into business wins, bridging the gap between technical promise and real-world impact.
{kind=link}