Introducing TPOT, the Data Science Assistant
Published on November 16, 2015 by Dr. Randal S. Olson
automation data science evolutionary computing machine learning pipeline python
5 min READ
Some of you might have been wondering what the heck I've been up to for the past few months. I haven't been posting much on my blog lately, and I haven't been working on important problems like solving Where's Waldo? and optimizing road trips around the world. (I promise: I'll get back to fun posts like that soon!) Instead, I've been working on something far geekier, and I'm excited to finally have something to show for it.
Over the summer, I started a new postdoctoral research position funded by the NIH at the University of Pennsylvania Computational Genetics Lab. During my first month there, I started looking for big problems in the field of data science to take on. Science (especially computer science) is often too incremental, and if I was going to stay in academia, I wanted to tackle a big problem. It was around that time that I started thinking about the process of machine learning and how we could let machines solve problems themselves rather than needing input from humans.
You see, machine learning is transforming the world as we know it. Google search engines were massively improved by machine learning, as were Gmail's spam filters. Voice assistants like Siri -- as silly as they can be -- use machine learning to translate your voice into something the computer can understand. Stock market investors make millions every day using machine learning to predict when to buy and sell. And the list goes on and on...

Ever wonder how Facebook always knows who you are in your photos? They use machine learning.
The problem with machine learning is that building an effective model can require a ton of human input. Humans have to figure out the right way to transform the data before feeding it to the machine learning model. Then they have to pick the right machine learning model that will learn from the data best, and then there's a whole bunch of model parameters to tweak that can make the difference between a dud and a Nostradamus-like model. Building these pipelines -- i.e., sequences of steps that turn the raw data into a predictive model -- can easily take weeks of tinkering depending on the difficulty of the problem. This is obviously a huge issue when machine learning is supposed to allow machines to learn on their own.
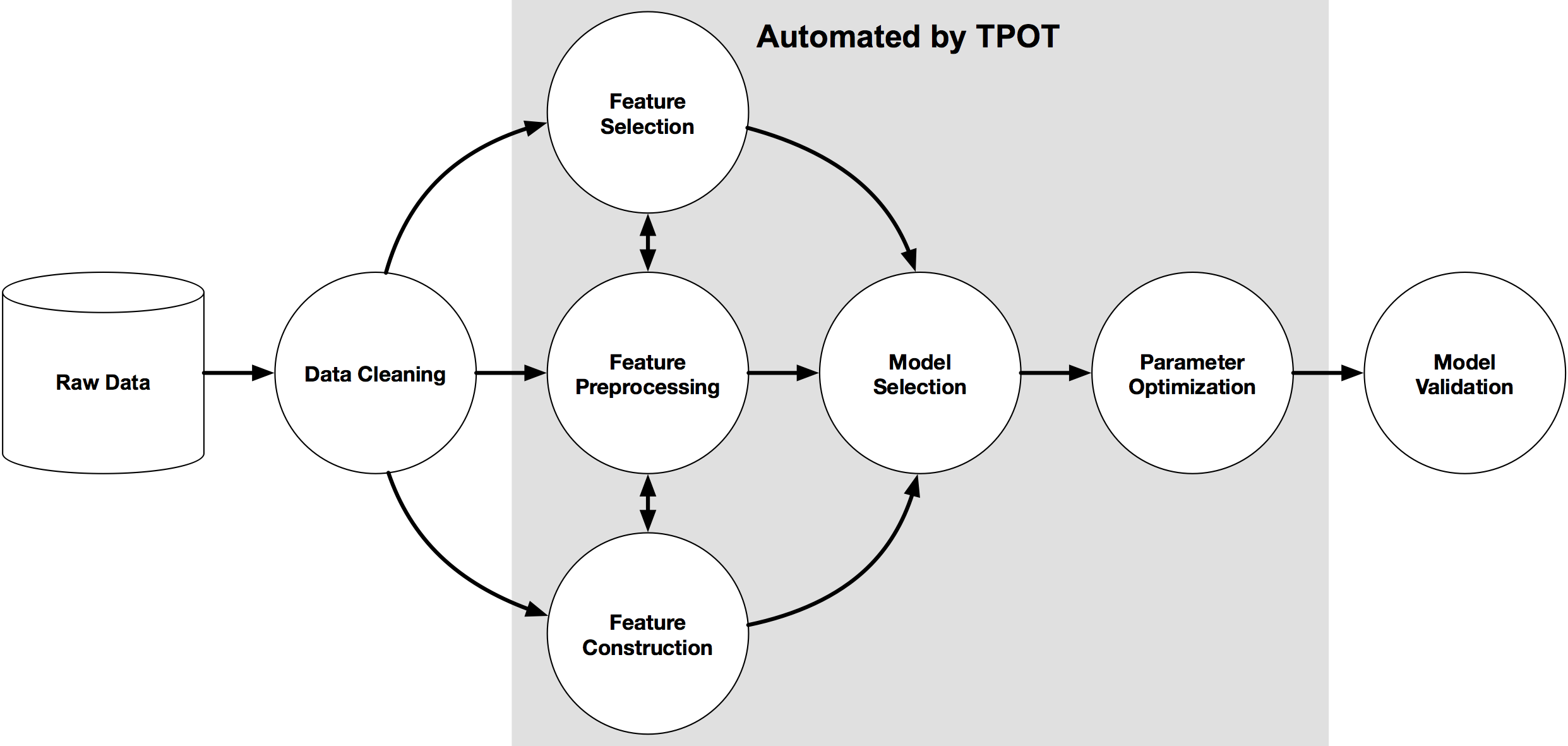
An example machine learning pipeline, and what parts of the pipeline TPOT automates
Thus, the Tree-based Pipeline Optimization Tool (TPOT) was born. TPOT is a Python tool that automatically creates and optimizes machine learning pipelines using genetic programming. Think of TPOT as your "Data Science Assistant": TPOT will automate the most tedious part of machine learning by intelligently exploring thousands of possible pipelines, then recommending the pipelines that work best for your data.
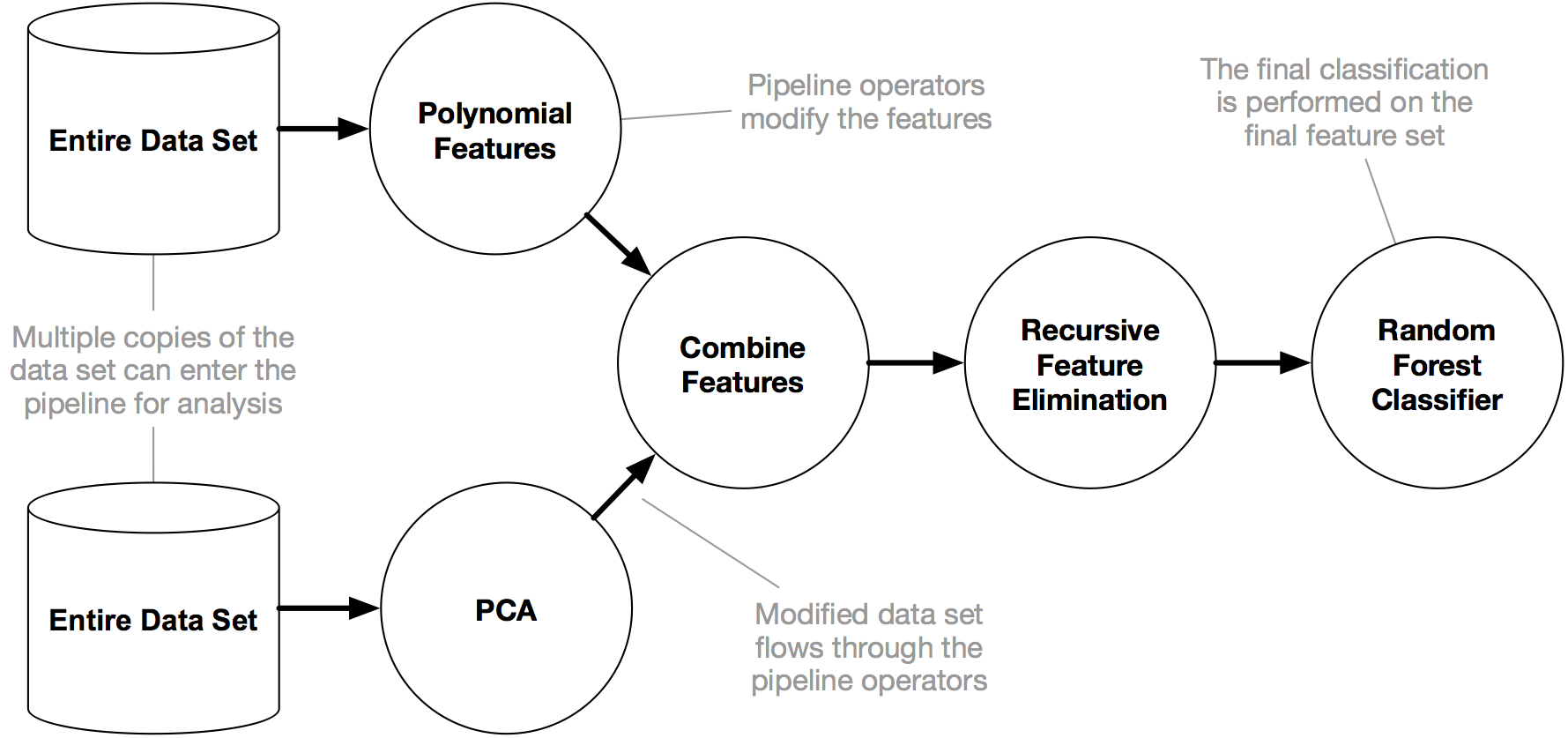
An example TPOT pipeline with two copies of the data set entering the pipeline.
Once TPOT is finished searching (or you get tired of waiting), it provides you with the Python code for the best pipeline it found so you can tinker with the pipeline from there. As an added bonus, TPOT is built on top of scikit-learn, so all of the code it generates should look familiar... if you're familiar with scikit-learn, anyway.
TPOT is still under active development and in its early stages, but it's worked very well on the classification problems I've applied it to so far.
Check out the TPOT GitHub repository to see the latest goings on. I'll be working on TPOT and pushing the boundaries of machine learning pipeline optimization for the majority of my postdoc.
An example using TPOT
I wanted to make TPOT versatile, so it can be used on the command line or via Python scripts. You can look up the detailed usage instructions on the GitHub repository if you're interested.
For this post, I've provided a basic example of how you can use TPOT to build a pipeline that classifies hand-written digits in the classic MNIST data set.
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
tpot = TPOTClassifier(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
After 10 or so minutes, TPOT will discover a pipeline that achieves roughly 98% accuracy. In this case, TPOT will probably discover that a random forest classifier and k-nearest-neighbor classifier does very well on MNIST with only a little bit of tuning. If you give TPOT even more time by setting the "generations" parameter to a higher number, it may find even better pipelines.
"TPOT sounds cool! How can I get involved?"
TPOT is an open source project, and I'm happy to have you join our efforts to build the best tool possible. If you want to contribute some code, check the existing issues for bugs or enhancements to work on. If you have an idea for an extension to TPOT, please file a new issue so we can discuss it.
tl;dr in image format
Justin Kiggins had a great summary of TPOT when I first tweeted about it:
@randal_olson pic.twitter.com/ds5iTbA2oF
— Justin Kiggins (@neuromusic) November 13, 2015
Anyway, that's what I've been up to lately. I'm looking forward to presenting TPOT at several research conferences in the coming months, and I'd really like to see what the machine learning community thinks about pipeline automation. In the meantime, give TPOT a try and let me know what you think.