A data-driven exploration of the evolution of chess: Popularity of openings over time
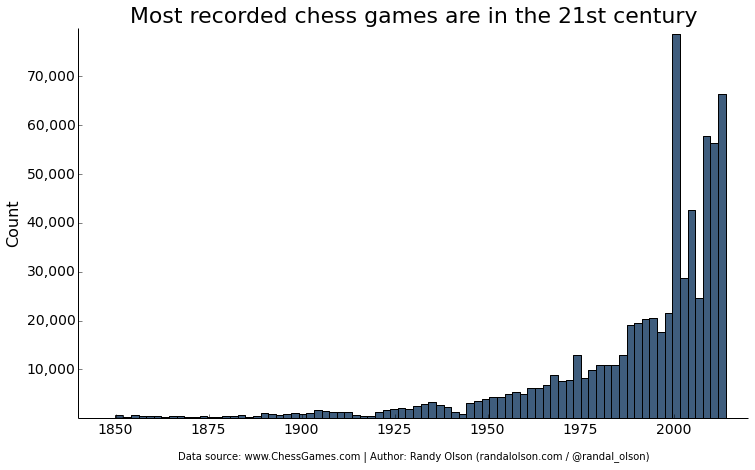
For the 3rd installment in my series of blog posts exploring a data set of over 650,000 chess tournament games ranging back to the 15th century, I wanted to look at how chess openings have grown and waned in popularity over time. Again, I only have reliable data on chess games back to 1850, so 1850 will be my starting point.
The first few moves of a chess game, known as the chess opening, are one of the most-studied aspects of the game, largely because of how important they can be. If you don't start off with a good opening, you could doom yourself to defeat before the game really even begins. It's therefore no surprise that one of the key steps to becoming a skilled chess player is studying and memorizing the many varieties of openings. Hundreds of openings have been developed since 1850, so it should make for an interesting exercise to see how these openings have evolved since then.
Each chess game is recorded in PGN format, which means that it stores every move each player made, the outcome of the game, etc. Here's an example game in PGN format:
[Event "Hoogovens A Tournament"]
[Site "Wijk aan Zee NED"]
[Date "1999.01.20"]
[EventDate "?"]
[Round "4"]
[Result "1-0"]
[White "Garry Kasparov"]
[Black "Veselin Topalov"]
[ECO "B06"]
[WhiteElo "2812"]
[BlackElo "2700"]
[PlyCount "87"]
1. e4 d6 2. d4 Nf6 3. Nc3 g6 4. Be3 Bg7 5. Qd2 c6 6. f3 b5
7. Nge2 Nbd7 8. Bh6 Bxh6 9. Qxh6 Bb7 10. a3 e5 11. O-O-O Qe7
12. Kb1 a6 13. Nc1 O-O-O 14. Nb3 exd4 15. Rxd4 c5 16. Rd1 Nb6
17. g3 Kb8 18. Na5 Ba8 19. Bh3 d5 20. Qf4+ Ka7 21. Rhe1 d4
22. Nd5 Nbxd5 23. exd5 Qd6 24. Rxd4 cxd4 25. Re7+ Kb6
26. Qxd4+ Kxa5 27. b4+ Ka4 28. Qc3 Qxd5 29. Ra7 Bb7 30. Rxb7
Qc4 31. Qxf6 Kxa3 32. Qxa6+ Kxb4 33. c3+ Kxc3 34. Qa1+ Kd2
35. Qb2+ Kd1 36. Bf1 Rd2 37. Rd7 Rxd7 38. Bxc4 bxc4 39. Qxh8
Rd3 40. Qa8 c3 41. Qa4+ Ke1 42. f4 f5 43. Kc1 Rd2 44. Qa7 1-0
With a bit of text parsing, I can count the number of times each chess opening was used on a per-game basis. For this analysis, I'll look at the openings in four classes: White's first move, Black's first move, White's second move, and Black's second move.
White's first move
It's a well-known fact that White has a small advantage at the beginning of the game. To maintain this advantage, White should press their advantage to take over the middle of the board as quickly as possible. The most popular first White moves from 1850-2014 are shown below. Note that all of these are fairly aggressive openings that build toward control of the middle of the board.
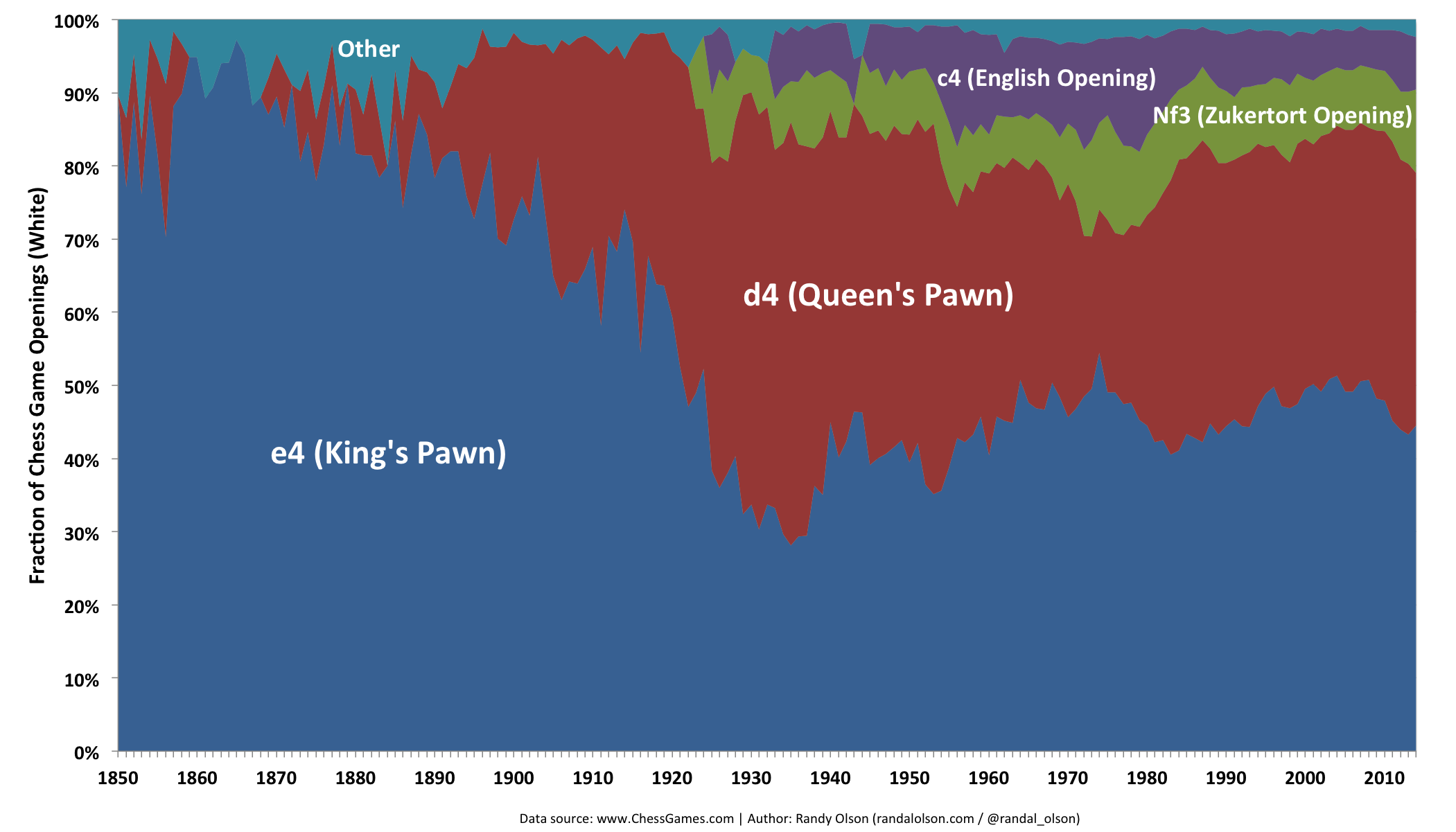
In 1850, White openings were fairly homogeneous: Most chess experts played King's Pawn. Chess players didn't begin to explore variants of the King's Pawn in earnest until the 1890s, when Queen's Pawn (moving a Pawn to d4) started to replace King's Pawn in some player's repertoires. The 1920s saw another burst of innovation with the rising popularity of the Zukertort Opening (moving the Knight to f3) and the English Opening (moving a Pawn to c4), which completed the set of staple first-turn openings that are really ever used nowadays.
Black's first move
Many of Black's opening moves are more defensive in nature and attempt to undermine White's initial advantage. In 1850, it was standard fare for Black to match the ever-popular King's Pawn by moving a Pawn to e5 (the Open Game). Although I typically group unpopular openings into the "Other" category, I wanted to point out the short-lived spike in popularity of the Pirc Defence in the 1850s. Though the Pirc Defence is typically thought of as a relatively new opening, Moheschunder Bannerjee used this opening almost exclusively in his 50+ games against John Cochrane, winning 40% of the games (far above his overall 24% win rate as Black).
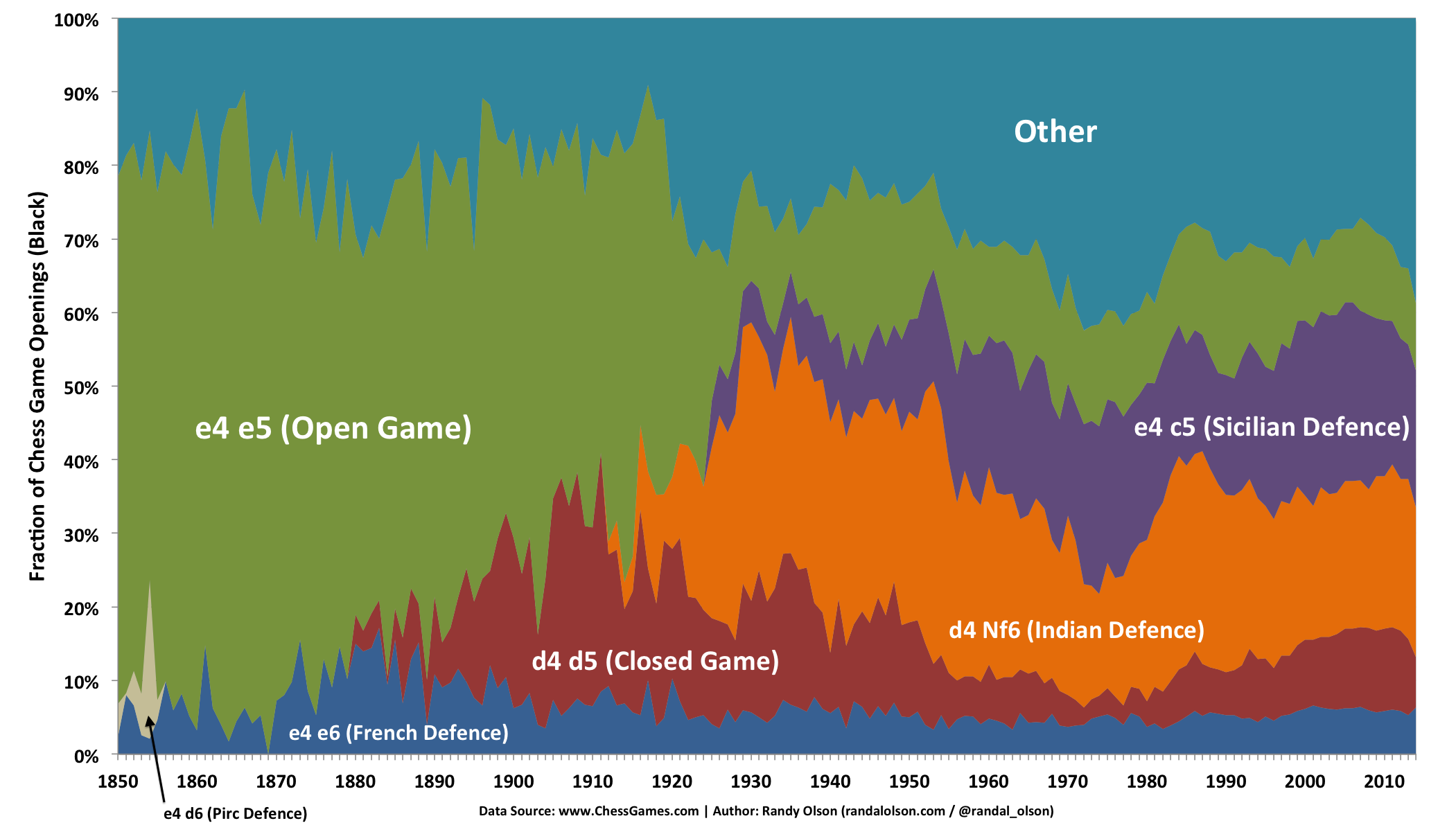
Moreover, the rise of the Queen's Pawn in the 1890s resulted in the rise of the Closed Game in the 1890s. Black openings similarly saw a burst of innovation in the 1920s, with the development of the Indian Defence in response to the Queen's Pawn, and the introduction of the ever-popular Sicilian Defence in response to the standard King's Pawn. By 2014, the Open Game is well past its glory days, and seems to be on its way out.
The French Defence seems to have been a staple Black opening for the past 164 years, consistently comprising 5%-10% of all chess games. Amusingly, the French Defence has a reputation for solidity and resilience, which is also reflected in its historical usage.
White's second move
Here's where things get complicated. I noted in the first section that the most popular first moves for White have historically been King's and Queen's Pawn, so that's why the more popular second moves for White exclusively start with them. The Zukertort and English Openings simply haven't become popular enough yet for their followup moves to show up here.
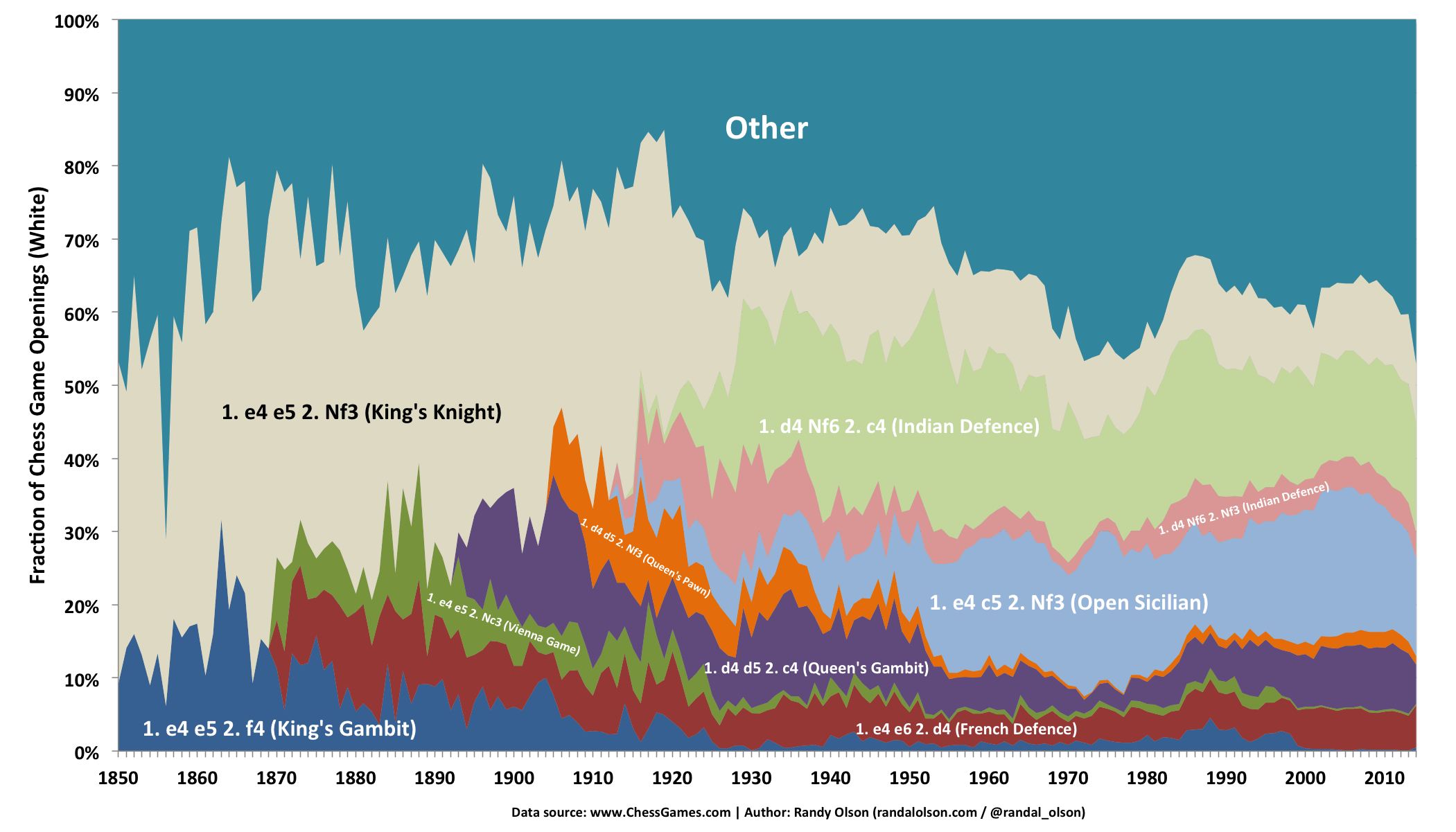
With the waning popularity of the Open Game over time, it's no surprise that the responses to it have similarly declined. By 2014, the typical response to the Open Game is to play the King's Knight, with the once-popular King's Gambit and Vienna Game becoming all but extinct. The Sicilian Defence's explosive rise to popularity is again reflected here, with the Open Sicilian (Knight to f3) becoming White's standard response. Again, White's response to Black's French Defence (moving a Pawn to d4) has remained consistently popular over time, rarely dropping below 5% of the games played each year.
To avoid being overly wordy here, I'll allow the visualization to speak for itself and leave the reader to explore the remaining trends as they please.
Black's second move
If you're familiar with chess, you know how quickly the set of possible moves grows with each move a player makes. After White and Black's first turn, the board will be in one of 400 unique positions. After their second turn, there are 197,742 possible positions. And after only 3 turns, 121 million possible positions. This means that if you play enough chess, it's highly likely that you will play a game that no one has ever played in the history of our universe. You can only imagine how difficult it would be to visualize all possible chess moves even up to the third turn.
Despite the infinite possibility in chess, there appears to be a strong bias toward a small subset of openings. In this data set, there were roughly 4,000 unique openings, and the 30 most popular ones comprise 70% of all chess games. Below is a visualization of the distribution of those 30 most popular openings from 1850-2014.
(Have any thoughts on a better way to visualize this data? Please leave them in the comments! I've already reached the limit of what area charts can effectively visualize by Black's second move.)
Interestingly, chess appears to be becoming more diverse over time. Whereas there were less than 100 unique openings by the end of both player's second turn in 1850, there were over 1,000 unique openings by 2014. This may be an artifact of the data set, however, because there are far more games recorded in the 21st century in this data set.
That's it for today. In the next installment, I'll be looking at more higher-level features of player strategy over time.

Dr. Randal S. Olson
AI Researcher & Builder · Co-Founder & CTO at Goodeye Labs
I’ve worked in AI for 15+ years. At Goodeye Labs, we build AI products that point frontier models at the business outcomes a team actually cares about.

{kind=link}